OCRBench v2: An Improved Benchmark for Evaluating Large Multimodal Models on Visual Text Localization and Reasoning
Scoring the Optical Character Recognition (OCR) capabilities of Large Multimodal Models (LMMs) has witnessed growing interest recently. Existing benchmarks have highlighted the impressive performance of LMMs in text recognition; however, their abilities in certain challenging tasks, such as text localization, handwritten content extraction, and logical reasoning, remain underexplored. To bridge this gap, we introduce OCRBench v2, a large-scale bilingual text-centric benchmark with currently the most comprehensive set of tasks (4X more tasks than the previous multi-scene benchmark OCRBench), the widest coverage of scenarios (31 diverse scenarios including street scene, receipt, formula, diagram, and so on), and thorough evaluation metrics, with a total of 10,000 human-verified question-answering pairs and a high proportion of difficult samples. After carefully benchmarking state-of-the-art LMMs on OCRBench v2, we find that 36 out of 38 LMMs score below 50 (100 in total) and suffer from five-type limitations, including less frequently encountered text recognition, fine-grained perception, layout perception, complex element parsing, and logical reasoning.
Project Page | Paper(Coming soon) | OCRBench v2 Leaderboard

Data
You can download OCRBench v2 from Google Drive After downloading and extracting the dataset, the directory structure is as follows:
OCRBench_v2/
├── EN_part/
├── CN_part/
├── OCRBench_v2.json
Evaluation
Environment
All Python dependencies required for the evaluation process are specified in the requirements.txt. To set up the environment, simply run the following commands in the project directory:
conda create -n ocrbench_v2 python==3.10 -y
conda activate ocrbench_v2
pip install -r requirements.txt
Inference
To evaluate the model's performance on OCRBench v2, please save the model's inference results in the JSON file within the predict field.
Example structure of the JSON file:
{
[
"dataset_name": "xx",
"type": "xx",
"id": 0,
"image_path": "xx",
"question": "xx",
"answers": [
"xx"
],
"predict": "xx"
]
...
}
Evaluation Scripts
After obtaining the inference results of the model, you can see use the bellow scripts to obtain the final score of OCRBench v2. ./pred_folder/internvl2_5_26b.json is an example inference result of InternVL2.5-26B with VLMEvalKit. You can use ./eval_scripts/eval.py to get the score for each samples, and the results are saved under ./res_folder.
python ./eval_scripts/eval.py --input_path ./pred_folder/internvl2_5_26b.json --output_path ./res_folder/internvl2_5_26b.json
After obtaining the scores for all samples, you can use ./eval_scripts/get_score.py to get the metrics for OCRBench v2.
python ./eval_scripts/get_score.py --json_file ./res_folder/internvl2_5_26b.json
Leaderboard
Performance of LMMs on English subsets
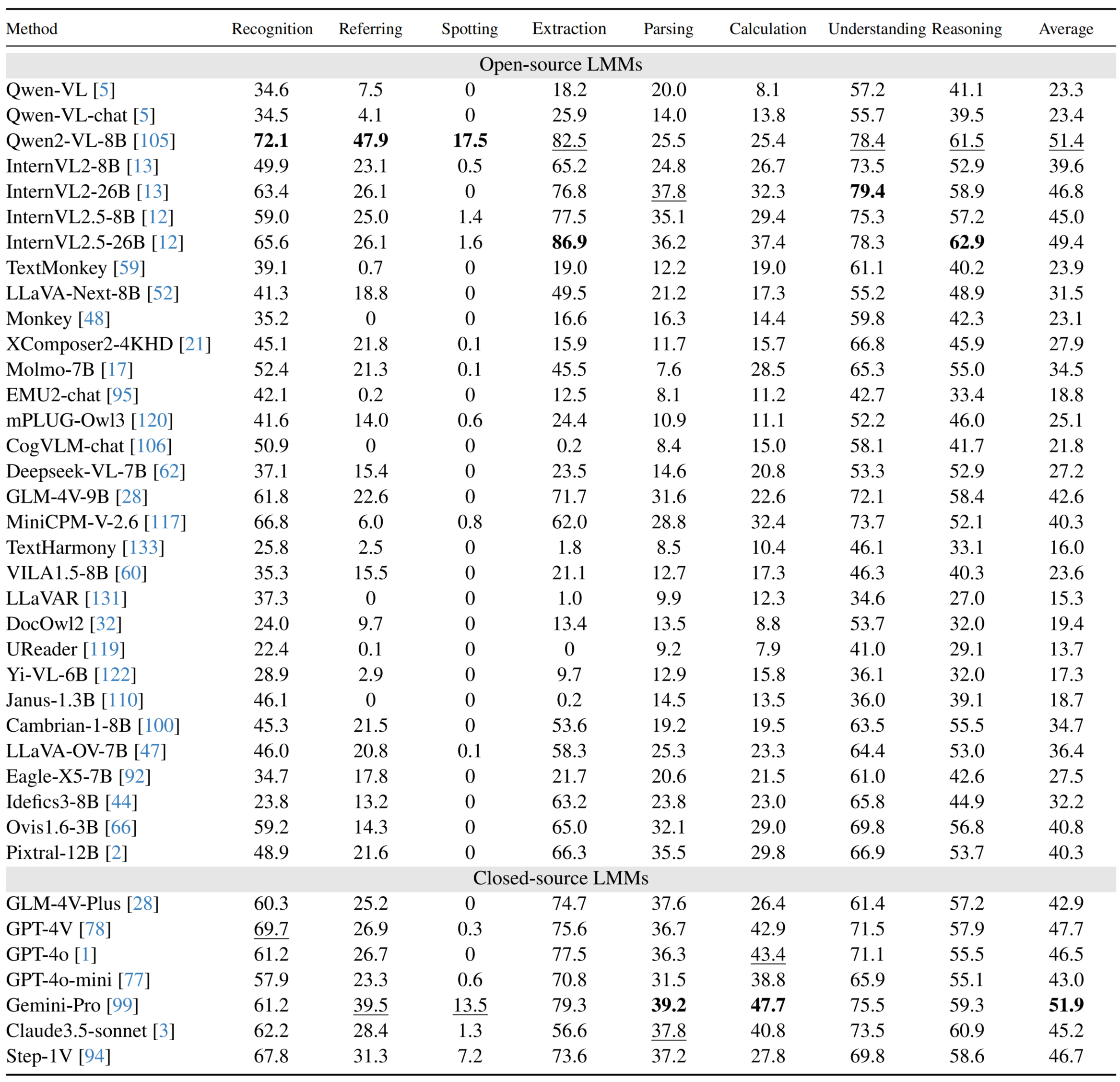
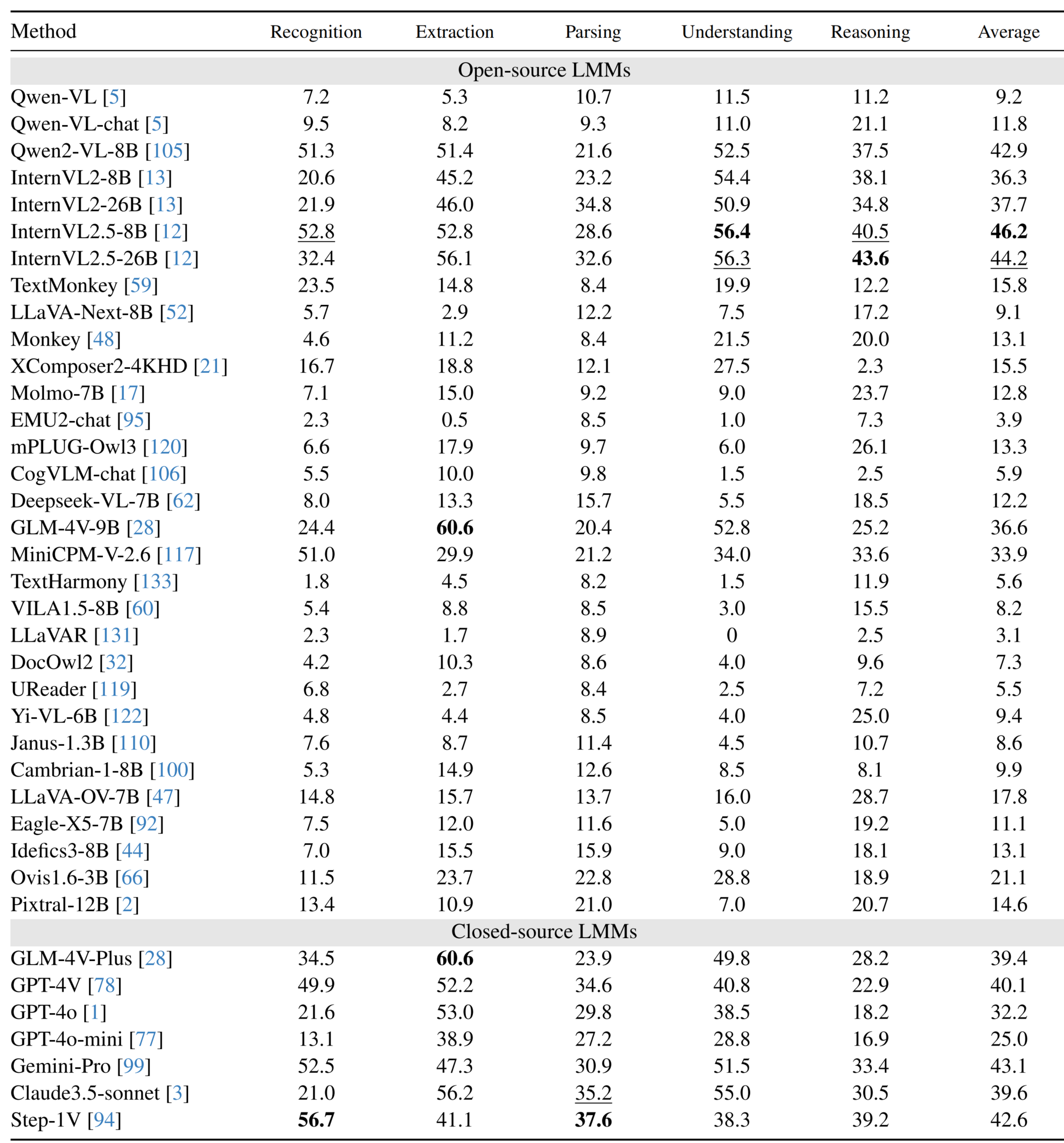
Performance of LMMs on Chinese subsets
Copyright Statement
The data are collected from public datasets and community user contributions. This dataset is for research purposes only and not for commercial use. If there are any copyright concerns, please contact ling_fu@hust.edu.cn.
Citation
Coming soon